Last week Google announced that they would be teaming up with Reddit to acquire their historical archive to train their AI models. Human written archives are becoming more and more valuable as AI models and their use cases become more prevalent. In the financial services industry language models can be incredibly useful for algo trading, as well as simply facilitating informed decision-making.
Now imagine having a tool that not only finds insights into stocks and articles but also breaks down how News impacts the market and its sentiments in a straightforward manner. This is not just an idea; it’s a reality made possible by the vast and valuable data archive that the Benzinga Newsdesk has contributed to over the last 14 years. The Benzinga News S3 bucket houses an extraordinary source of comprehensive data with the potential to power any Large Language Model (LLM), especially one related to finance.
I’ll guide you through each step, revealing the process of creating your own intelligent assistant. This assistant will excel in reading, summarizing, gaining insights, and analyzing sentiments. Our journey begins by tapping into the data stored in Benzinga’s S3 bucket. We’ll explore how to preprocess this data, a crucial step in extracting meaningful insights. Subsequently, armed with refined information, we’ll delve into the articles, unveiling essential market insights.
What are S3 buckets and AWS?
AWS, or Amazon Web Services, is like a gigantic toolbox of cloud computing services provided by Amazon. It offers a variety of tools and resources that individuals and businesses can use to run applications, store data, and perform various tasks without needing to set up their own physical servers. Essentially, AWS provides a convenient and flexible way to access computing power and services over the Internet.
S3 buckets are like containers where you can store and organize your files, such as photos, videos, or documents. Think of them as virtual buckets where you can keep your data safe, and easily access or share it over the internet whenever you need. It’s a simple and efficient way to manage your digital stuff in the cloud.
Obtaining the Benzinga stock news dataset using AWS S3 buckets
In this section, we will access the data from the Benzinga’s AWS news database.
1. We need to install and configure the AWS command line interface first. You can find the download link and instructions here.
2. After installation, you can access AWS from your command line or terminal. Check it through the command:
aws – version
3. Now, we will configure the command line to access Benzinga containers. Here, you will be asked the username, password, region name, and output format. Use the following command and enter the necessary details for your S3 bucket:
aws configure
4. Once this is done we can access the specific bucket from the AWS account using the command to list all the files or folders there.
aws s3 ls bucket_url
Replace your bucket url from this. Once you cd your self to the directory which you want to download.
5. Use this command to save it to your desired folder
aws s3 cp bucket_url path_to_save_folder_ –recursive
The data will be downloaded to the specified folder in the format json.gz
Converting and Preprocessing Data
Now armed with our treasure of data, we move on to the crucial step of converting it into a more understandable format – CSV. A Python script is introduced, demonstrating how to extract and convert JSON data into a CSV file. This step ensures that our model comprehends the data effectively, setting the stage for insightful analysis.
We will now convert the data to CSV format so that the model understands it. Along with that, we will also preprocess the data:
import json
import gzip
import csv
import os
# Function to extract and convert JSON data to CSV
def json_to_csv(input_folder, output_csv):
with open(output_csv, 'w', newline='', encoding='utf-8') as csv_file:
csv_writer = csv.writer(csv_file)
# Write the header
csv_writer.writerow(["id", "author", "created", "updated", "title", "teaser", "body", "url"])
# Loop through each JSON file in the folder
for filename in os.listdir(input_folder):
if filename.endswith(".json.gz"):
file_path = os.path.join(input_folder, filename)
with gzip.open(file_path, 'rt', encoding='utf-8') as json_file:
data = json.load(json_file)
print(data)
# Extract relevant fields and write to CSV
csv_writer.writerow([
data.get("id", ""),
data.get("author", ""),
data.get("created", ""),
data.get("updated", ""),
data.get("title", ""),
data.get("teaser", ""),
data.get("body", ""),
data.get("url", "")
])
# Specify the input folder containing JSON files and the output CSV file
input_folder = "D:\\Scriptonomy Python Developer\\ph\\01\\01"
output_csv = "202301---1.csv"
# Call the function to convert JSON to CSV
json_to_csv(input_folder, output_csv)
The provided Python script defines a function, json_to_csv, aimed at converting a collection of gzipped JSON files in a specified input folder into a CSV format. The function iterates through each file, extracts relevant fields such as “id,” “author,” “created,” and others, and then writes this information as rows into a CSV file.
The script utilizes standard Python libraries such as JSON, GZIP, CSV, and OS for handling JSON data, decompressing files, managing CSV operations, and interacting with the file system. After defining the function, the script specifies the input folder path containing the JSON files and designates an output CSV file. Finally, the script invokes the json_to_csv function, initiating the conversion process and producing a CSV file with the extracted information from the JSON files.
Making your own article assistant
Finally, we explore the realm of creating your own article assistant powered by OpenAI’s language model (GPT-3.5-turbo). This assistant aids in sentiment analysis and provides insights into how the information in an article influences market conditions and prices.
Importing the necessary packages that will help in managing the resources, all these if not present in the environment can be installed with !pip install package_name.
import openai
import pandas as pd
from bs4 import BeautifulSoup
# openai.api_key = "YOUR_API_KEY"
- OpenAI acts as a vast source of LLMs and its applications
- Pandas is used for handling the data, it comes with lots of inbuilt functions to help ease many important processes.
- BeautifulSoup is used for extracting data from various sources.
# openai.api_key = "YOUR_API_KEY"
The following function connects with gpt-3.5-turbo and configures the model with prompt and response.
def get_chatcompletion(prompt, model="gpt-3.5-turbo"):
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0, # this is the degree of randomness of the model's output
)
return response.choices[0].message["content"]
df = pd.read_csv('the_path_to_savedCSV')
df
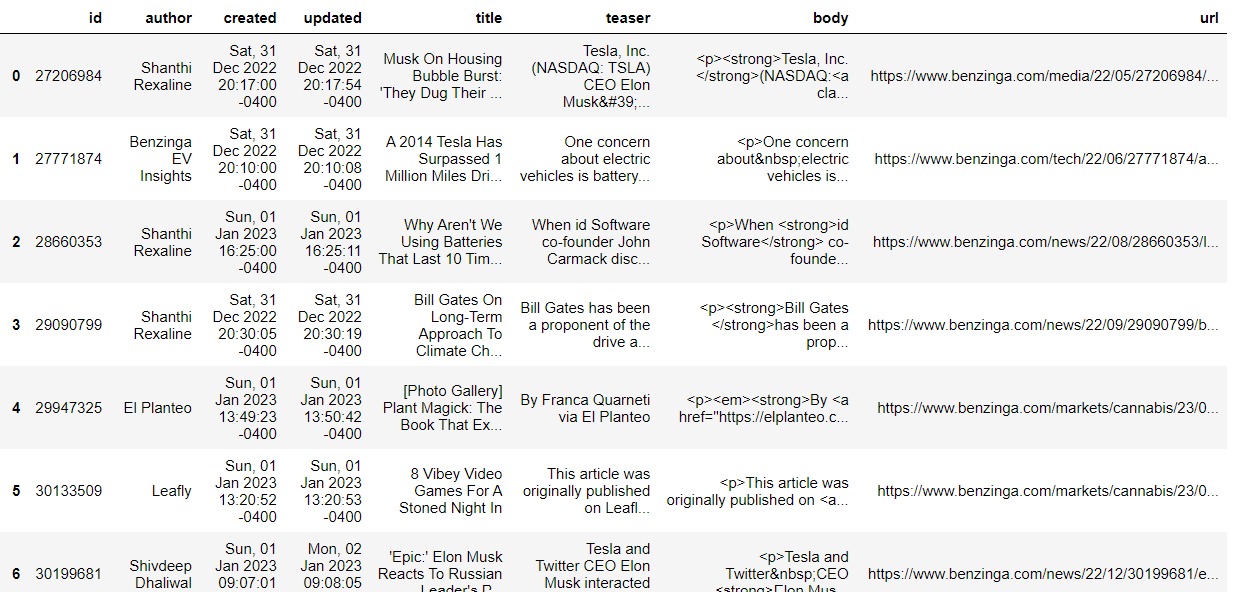
The dataset contains information about various articles, each represented by a row. The columns include ‘id’ (article identifier), ‘author’ (author’s name), ‘created’ (creation timestamp), ‘updated’ (last update timestamp), ‘title’ (article title), ‘teaser’ (a brief summary of the article), ‘body’ (the main content of the article), and ‘url’ (the URL where the full article can be accessed).
The data covers articles on diverse topics, such as Elon Musk’s thoughts on a housing bubble, the mileage achievement of a 2014 Tesla, discussions on long-lasting batteries, Bill Gates’ perspective on climate change, a photo gallery on plant magic, and a list of video games for a night in. The dataset seems to capture a range of articles from different authors and topics within the specified timeframe.
The following functions clean the body of the article of the HTML and other impurities so that the model gives the best output.
def cleaner(text):
soup = BeautifulSoup(text, 'html.parser')
# Extract text without HTML tags
text_without_html = soup.get_text()
return text_without_html
df['body'] = df['body'].apply(cleaner)
Now we give instructions to the model to give sentiments, insights related to the market, and the explanation behind the output it is giving. Following the chain of thoughts prompting, explained in the paper, Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. As explained in the paper asking for justifications improve models performance.
Chain of Thought Prompting
In chain-of-thought prompting, the input question is followed by a series of intermediate natural language reasoning steps that lead to the final answer. Think of this as breaking down a complicated task into bite-sized, logical chunks.
prompt = f"""
You are a sentiment analyser and your task is to predict the sentiment on a stock news article on a scale of 1 to 10,
1 being most negative, 10 being most positive and 5 being neutral. Give the explanation for your ratings and also give insights
how the information given in the article will affect the market conditions and prices, point wise and relate it with current market
conditions.
Article: {df['body'][0]}
"""
response = get_chatcompletion(prompt)
print(response)

The response includes all the important details that one needs to understand the article and make important decisions based on stock news.
Conclusion
In summary, this article introduces a powerful solution for staying informed about financial markets by combining Benzinga’s robust News content and Artificial Intelligence. It guides readers through accessing Benzinga’s stock news dataset using AWS S3 buckets, converting and preprocessing the data with a Python script, and creating a personalized article assistant using OpenAI’s GPT-3.5-turbo. The approach enables sentiment analysis, insightful market predictions, and decision-making based on a diverse set of articles.


